Bar codes are like a
printed version of the Morse code. Different bar and space
patterns are used to represent different characters. Sets of
these patterns are grouped together to form a "symbology".
There are many types of bar code symbologies each having their
own special characteristics and features. Most symbologies were
designed to meet the needs of a specific application or a
specific industry. For example the UPC symbology was designed
for identifying retail and grocery items and PostNET was
designed to encode Zip Codes for the US Postal Service
|
CODE 39 (Normal
and Full ASCII versions)
 |
| The Normal CODE 39 is a
variable length symbology that can encode the following 44
characters: 1234567890ABCDEFGHIJKLMNOPQRSTUVWXYZ-. *$/+%. Code
39 is the most popular symbology in the non retail world and is
used extensively in manufacturing, military, and health
applications. Each Code 39 bar code is framed by a start/stop
character represented by an asterisk (*). The Asterisk is
reserved for this purpose and may not be used in the body of a
message. B-Coder automatically adds the start and stop character
to each bar code therefore you should not include them as part
of your bar code message. If you select the NORMAL version of
CODE 39 and your bar code text contains lower case characters,
B-Coder will convert them to upper case. If your bar code
message contains any invalid characters, B-Coder will prompt you
with a warning message (if the Enable Invalid Warning Messages
option is selected in the Preferences menu). |
Code 39 optionally allows for a (modulo 43) check
character in cases where data security is important. The health
care industry has adopted the use of this check character for
health care applications. To enable the Code 39 check character
feature in B-Coder, select the option INCLUDE CODE 39 /
I 2 of 5 CHECK CHARACTER in B-Coder's Preferences menu.
When this option is enabled, B-Coder will automatically
calculate and append the proper check character to all Code 39
symbols. |
Another feature of Code 39 allows for concatenation of two or
more bar codes. It is sometimes advantageous to break long
messages into multiple, shorter, symbols. If the first data
character of a Code 39 symbol is a space, some readers will
store the remainder of the symbol in a buffer and
not transmit the data. This operation continues for all
successive Code 39 symbols with a leading space, with each
message appended to the previous one.
When a message without a leading space is read, it is
appended to the previously scanned data in the buffer and the
entire buffer is transmitted as one long message. |
The FULL ASCII version of Code 39 is a modification of
the NORMAL (standard) version that can encode the complete 128
ASCII character set (including asterisks). The Full ASCII
version is implemented by using the four characters: $/+%. as
shift characters to change the meanings of the rest of the
characters in the Normal Code 39 character set. Because the Full
ASCII version uses shift characters in combination with other
standard characters to represent data not in the Normal Code 39
character set, each non-standard character requires twice the
width of a standard character in a printed symbol.
Note: Because all of the characters
used to implement Full ASCII Code 39 are part of the Normal Code
39 character set, readers that do not support Full ASCII Code 39
will still read Full ASCII Code 39 symbols. The reader will
output shifted characters as if they were normal Code 39
characters.
|
UPC-A,
UPC-E, and UPC Supplementals
UPC-A with Supplemental UPC-E |
  |
| UPC-A is a 12 digit,
numeric symbology used in retail applications. UPC-A symbols
consist of 11 data digits and one check digit. The first digit
is a number system digit that usually represents the type of
product being identified. The following 5 digits are a
manufacturers code and the next 5 digits are used to identify a
specific product.
UPC numbers are assigned to
specific products and manufacturers by the Uniform Code Council
(UCC). To apply for a UPC number or for more information, you
can contact the UCC at 8163 Old Yankee Road, Suite J, Dayton, OH
45458 Tel: 937-435-3870
When specifying UPC-A messages, you may enter up to 11 digits.
B-Coder will automatically calculate the check digit for you. If
you enter less than 11 digits or if you enter any digits other
than 0 to 9, B-Coder will prompt you with a warning message. If
the option "Enable Invalid Message Warnings" in the
Preferences menu is not selected and you do not enter 11 digits,
B-Coder will left pad short messages with zeros and truncate
longer messages so that the total length is 11.
UPC-E is a smaller, six digit, UPC symbology for number system
0. It is often used for small retail items. UPC-E is also called
"zero suppressed" because UPC-E compresses a normal 12
digit UPC-A code into a six digit code by
"suppressing" the number system digit, trailing zeros
in the manufacturers code and leading zeros in the product
identification part of the bar code. A seventh check digit is
encoded into a parity pattern for the six main digits. UPC-E can
thus be uncompressed into a standard UPC-A 12 digit number.
For UPC-E bar codes, you may enter up to 6 digits. Again,
B-Coder will calculate the check digit and truncate or pad the
number to a total length of 6 digits as with UPC-A.
Both UPC-A and UPC-E allow for a supplemental two or five digit
number to be appended to the main bar code symbol. This
supplemental message was designed for use on publications and
periodicals. If you enter a supplemental message, it must
consist of either two or five numeric digits. The supplemental
is simply a small additional bar code that is added onto the
right side of a standard UPC symbol.
|
EAN-8
/ EAN-13, BookLan and EAN Supplementals
EAN-8 EAN-13 with
supplemental (ISBN Version)
 
EAN or European Article Numbering
system (also called JAN in Japan) is a European version of UPC.
It uses the same size requirements and a similar encoding scheme
as for UPC codes.
EAN-8 encodes 8 numeric digits consisting of two country code
digits, five data digits and one check digit. B-Coder will
accept up to 7 numeric digits for EAN-8. B-Coder will
automatically calculate the check digit for you. If you enter
less than 7 digits or if you enter any digits other than 0 to 9,
B-Coder will display a warning message. If the option
"Enable Invalid Message Warnings" in the Preferences
menu is not selected and you do not enter 7 digits, B-Coder will
left pad short messages with zeros and truncate longer messages
so that the total length is 7.
EAN-13 is the Euro version of UPC-A. The difference between
EAN-13 and UPC-A is that EAN-13 encodes a 13th digit into the
parity pattern of the left six digits of a UPC-A symbol. This
13th digit, combined with the 12th digit, usually represent a
country code.
Both EAN-8 and EAN-13 support a supplemental two or five digit
number to be appended to the main bar code symbol. The
supplemental is designed for use on publications and
periodicals. Supplemental messages must consist of either two or
five numeric digits and will appear as a small additional bar
code on the right side of a standard EAN symbol.
EAN bar code numbers are assigned to specific products and
manufacturers by an organization called ICOF located in
Brussels, Belgium. Tel: 011-32-2218-7674
EAN-13 has been adopted as the standard in the publishing
industry for encoding ISBN numbers on books. An ISBN or BookLan
bar code is simply an EAN-13 symbol consisting of the ISBN
number preceded by the digits 978. The supplemental in an ISBN
bar code is simply the retail price of the book preceded by the
digit 5. For example, if your ISBN number is 1-56276-008-4 and
the price of the book is $29.95 then you would enter
978156276008 as the bar code message and 52995 for the
supplemental. If you choose BookLan as the bar code symbology,
B-Coder will automatically create the correct EAN-13 bar code if
you supply just the first 10 digits of the ISBN number and
optionally a price (without the preceding 5).
|
CODABAR

CodaBar is a variable length symbology
that allows encoding of the following 20 characters:
0123456789-$:/.+ABCD. CodaBar is commonly used in libraries,
blood banks, and the air parcel business. CodaBar uses the
characters A B C and D only as start and stop characters. Thus,
the first and last digits of a CodaBar message must be A B C or
D and the body of the message should not contain these
characters. B-Coder will allow any length of CodaBar message as
long as it contains valid characters and starts and ends with a
valid start/stop character. If you use lower case letters for A
B C or D, B-Coder will convert to upper case.
|
INTERLEAVED
2 OF 5

Interleaved 2 of 5 is a high density
variable length numeric only symbology that encodes digit pairs
in an interleaved manner. The odd position digits are encoded in
the bars and the even position digits are encoded in the spaces.
Because of this, I 2 of 5 bar codes must consist of an even
number of digits. Also, because partial scans of I 2 of 5 bar
codes have a slight chance of being decoded as a valid (but
shorter) bar code, readers are usually set to read a fixed
(even) number of digits when reading I 2 of 5 symbols. The
number of digits are usually pre-defined for a particular
application and all readers used in the application are
programmed to only accept I 2 of 5 bar codes of the chosen
length. Shorter data can be left padded with zeros to fit the
proper length. B-Coder will only accept numeric digits for I 2
of 5 bar codes. If an odd number of digits is entered, B-Coder
will Left-Pad one zero to the number entered.
Interleaved 2 of 5 optionally allows for a weighted modulo 10
check character for special situations where data security is
important. To enable the I 2 of 5 check character feature in
B-Coder, select the option INCLUDE CODE 39 / I 2 of 5 CHECK
CHARACTER in B-Coder's Preferences menu. When this option is
enabled, B-Coder will automatically calculate and append the
proper check character to all Interleaved 2 of 5 symbols.
|
DISCRETE
2 OF 5

Discrete 2 of 5 is a variable length
numeric symbology very similar to Interleaved 2 of 5 except that
instead of encoding data in both the bars and the spaces, data
is only encoded in the bars. Because of this, discrete 2 of 5 is
not as compact as Interleaved 2 of 5 and also, odd numbers of
digits may be encoded. Use of Discrete 2 of 5 is not very common
and few bar code readers support this symbology.
|
CODE
93

CODE 93 is a variable length symbology
that can encode the complete 128 ASCII character set. Code 93
was developed as an enhancement to the CODE 39 symbology by
providing a slightly higher character density than CODE 39. CODE
93 also incorporates two check digits as an added measure of
security. Although CODE 93 is considered more robust than CODE
39, it has never achieved the same popularity as Code 39. CODE
93 bar codes are framed by a special start/stop character.
B-Coder will automatically add the start and stop characters as
well as the check digits to each Code 93 bar code therefore you
should not attempt to include them as part of your bar code
message.
|
CODE
128

Code 128 is a variable length, high density, alphanumeric
symbology. Code 128 has 106 different bar and space patterns and
each pattern can have one of three different meanings, depending
on which of three different character sets is employed. Special
start characters tell the reader which of the character sets is
initially being used and three special shift codes permit
changing character sets inside a symbol. One character sets
encodes all upper case and ASCII control characters, another
encodes all upper and lower case characters and the third set
encodes numeric digit pairs 00 through 99. This third character
set effectively doubles the code density when printing numeric
data. Code 128 also employs a check digit for data security. In
addition to ASCII characters, Code 128 also allows encoding of
four special function codes (FNC1 - FNC4). The meaning of
function code FNC1 and FNC4 were originally left open for
application specific purposes. Recently an agreement was made by
the Automatic Identification Manufacturers Assoc. (AIM) and the
European Article Numbering Assoc. (EAN) to reserve FNC1 for use
in EAN applications. FNC4 remains available for use in closed
system applications. FNC2 is used to instruct a bar code reader
to concatenate the message in a bar code symbol with the message
in the next symbol. FNC3 is used to instruct a bar code reader
to perform a reset. When FNC3 is encoded anywhere in a symbol,
any data also contained in the symbol is discarded. The four
function codes can be added to a message by selecting them from
the bottom of the ASCII chart in B-Coder's window.
Note: B-Coder will automatically
select the proper character sets and insert the necessary start
character and shift codes so that the resulting bar code will be
as short as possible. The check digit will also be calculated
automatically by B-Coder.
|
EAN/UCC
128

The EAN/UCC 128 symbology is a variation of the original Code
128 symbology designed primarily for use in product
identification applications. The EAN/UCC 128 specification uses
the same code set as Code 128 except that it does not allow
function codes FNC2-FNC4 to be used in a symbol and FNC1 is used
as part of the start code in the symbol. The check digit in EAN/UCC128
symbols is also calculated differently than in Code 128.
|
POSTNET
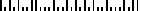
POSTNET (POSTal Numeric Encoding Technique) is a 5, 9 or 11
digit numeric only bar code symbology used by the U.S. Postal
Service to encode ZIP Code information for automatic mail
sorting by zip code. The bar code may represent a five digit ZIP
Code (32 bars), a nine digit ZIP + 4 code (52 bars) or an eleven
digit Delivery Point code (62 bars).
POSTNET is unlike other bar codes because data is encoded in the
height of the bars instead of in the widths of the bars and
spaces. Most standard bar code readers cannot decode POSTNET.
This symbology was chosen by the Postal Service mainly because
it is extremely easy to print on almost any type of printer.
POSTNET is a fixed dimension symbology meaning that the height,
width and spacing of all bars must fit within exact tolerances.
B-Coder will only create POSTNET bar codes that follow the
guidelines published by the Postal Service. B-Coder does not
allow direct control over the size of POSTNET bar codes.
NOTE: Most other Windows programs
allow you to modify the size of metafile graphic images pasted
from the clipboard. If you change the size of a POSTNET bar code
even by a small amount, it will be completely unreadable by the
Postal Service bar code readers.
B-Coder will ignore non-numeric data in any bar code message
that you enter for POSTNET. For example, if you enter
"Chicago, IL 60601-3222" for a POSTNET bar code
message,
B-Coder will still create a correct bar code. This feature
allows you to cut an address line from another Windows program
and paste it into B-Coder without having to edit the bar code
text.
|
Postal
FIM Patterns
FIM or Facing Identification Mark
patterns are another type of postal bar code used in automated
mail processing by the U.S. Postal Service. FIM patterns are
used for automatic facing and canceling of mail that does not
contain a stamp or meter imprint (business reply mail, penalty
mail, etc.). They also provide a means of separating business
and courtesy reply mail from other letters. Three FIM patterns
are currently in use. FIM-A is used on courtesy reply mail that
has been preprinted with PostNET bar codes. FIM-B is used on
business reply, penalty and franked (government) mail that is
not preprinted with PostNET bar codes. FIM-C is used on business
reply, penalty and franked mail that has been preprinted with
PostNET bar codes. FIM patterns are placed in the upper right
corner along the top edge and two inches in from the right edge
of letters and cards. For more information about all postal bar
codes contact your local post office.
When you select a FIM pattern from the symbology menu, B-Coder
will immediately generate the requested pattern without
switching from the currently selected symbology and without
having to select Build/Copy from B-Coder's Edit menu.
|
PDF417,
2 dimensional
bar code symbology

PDF417 is a high density 2 dimensional bar code symbology
that essentially consists of a stacked set of smaller bar codes.
The symbology is capable of encoding the entire (255 character)
ASCII set. PDF stands for "Portable Data File" because
it can encode as many as 2725 data characters in a single bar
code. The complete specification for PDF417 provides many
encoding options including data compaction options, error
detection and correction options, and variable size and aspect
ratio symbols. The symbology was published by Symbol
Technologies, Inc. to fulfill the need for higher density bar
codes. The low level structure of a PDF417 symbol consists of an
array of code words (small bar and space patterns) that are
grouped together and stacked on top of each other to produce the
complete printed symbol. An individual code word consists of a
bar and space pattern 17 modules wide. The user may specify the
module width, the module height, and the overall aspect ratio
(overall height to width ratio) for the complete symbol. A
complete PDF417 symbol consists of at least 3 rows of up to 30
code words and may contain up to 90 code word rows per symbol
with a maximum of 928 code words per symbol.
The code words in a PDF417 symbol are generated using one of
three data compaction modes currently defined in the symbology
specifications. This allows more than one character to be
encoded into a single data code word. Because different data
compaction algorithms may be used, it is possible for different
printed symbols to be created from the same input data. The
symbology also allows for varying degrees of data security or
error correction and detection. Nine different error correction
levels are available with each higher level adding additional
overhead to the printed symbol.
B-Coder allows complete control over all optional features of
PDF417.
|
BPO
4 State Code (British Post
Office, Royal Mail Code)
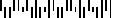
BPO (British Post Office) 4 State Code is a new postal
bar code symbology that has been developed by the British Post
office for encoding European postcode data similar to the way
the U.S. PostNET symbology is used for encoding Zip Code data.
At the time of this writing, the BPO 4 State Code has not been
officially adopted as the standard for European postal
applications however it is anticipated that it will be
sanctioned sometime in 1995. The goal of BPO 4 State Code is to
provide European countries with a simple and efficient postal
bar coding scheme.
The U.S. PostNET symbology encodes numeric characters in a
pattern of four bars per character with each bar being either
tall or short (i.e. two possible "states" for each
bar). The U.S. technique thus allows for up to 16 different
possible bar patterns for each set of four bars and is adequate
for encoding the ten digits zero through nine. Because European
postcodes contain both alpha and numeric characters, (thus
requiring a minimum of 36 different possible patterns for the
characters A-Z and 0 to 9), each character in the BPO 4 State
Code is encoded into four bars with each bar having four
possible "states". The four states are: tall bars,
short bars, medium height bars extended up from the middle of
the symbol and medium height bars extended down from the middle
of the symbol. In theory,the BPO 4 State Code is capable of
encoding up to 128 different characters however only the
characters A through Z and 0 to 9 have been assigned unique bar
patterns.
BPO 4 State Code is a fixed dimension symbology meaning that the
height, width and spacing of all bars must fit within exact
tolerances. B-Coder will only create BPO 4 State Code bar codes
that follow the guidelines published by the British Postal
Service. B-Coder does not allow direct control over the size of
BPO 4 State Code bar codes.
NOTE: Most other Windows programs
allow you to modify the size of metafile graphic images pasted
from the clipboard. If you change the size of a BPO 4 State Code
bar code even by a small amount, it will be completely
unreadable by European Postal Service bar code readers.
|
| DATA
MATRIX
Data Matrix is a high
density 2 dimensional matrix style bar code symbology that can
encode up to 3116 characters from the entire 256 byte ASCII
character set. The symbol is built on a square grid arranged
with a finder pattern around the perimeter of the bar code
symbol.
There are two types of Data
Matrix symbols each using a different error checking and
correction scheme (ECC). The different types of Data Matrix
symbols are identified using the terminology "ECC"
followed by a number representing the type of error correction
that is used by the encoding software. ECC 000 to ECC 140 are
the original type of Data Matrix symbols and are now considered
obsolete. The newest version of Data Matrix is called ECC 200
and is recommended for all new Data Matrix applications. The ECC
200 version of Data Matrix uses a much more efficient algorithm
for encoding data in a symbol as well as an advanced error
checking and correction scheme. The TAL Data Matrix bar code DLL
fully supports all variations of the Data Matrix symbology
however the author of the original symbology specification (CI
Matrix Co.) highly recommends that ECC 000 - ECC 140 be used
only where absolutely necessary.
|
| MAXICODE
MaxiCode is a fixed size
matrix style symbology which is made up of offset rows of
hexagonal modules arranged around a unique bulls-eye finder
pattern. Each MaxiCode symbol has 884 hexagonal modules arranged
in 33 rows with each row containing up to 30 modules. The
maximum data capacity for a MaxiCode symbol is 93 Alphanumeric
characters or 138 Numeric characters. The symbology was designed
by United Parcel Service for package tracking applications. The
design of the MaxiCode symbology was chosen because it is well
suited to high speed, orientation independent scanning. Although
the capacity of a MaxiCode symbol is not as high as other matrix
style bar code symbologies, it was primarily designed to encode
address data which rarely requires more than about 80
characters. MaxiCode symbols actually encode two separate
messages - a Primary message and a Secondary message. The
Primary message normally encodes a postal code, a 3 digit
country code and a 3 digit class of service number. The
Secondary message normally encodes address data and any other
required information.
|
| AZTEC
CODE
Aztec Code is a high
density 2 dimensional matrix style bar code symbology that can
encode up to 3750 characters from the entire 256 byte ASCII
character set. The symbol is built on a square grid with a
bullseye pattern at its center. Data is encoded in a series of
"layers" that circle around the bullseye pattern. Each
additional layer completely surrounds the previous layer thus
causing the symbol to grow in size as more data is encoded yet
the symbol remains square. Aztec's primary features include: a
wide range of sizes allowing both small and large messages to be
encoded, orientation independent scanning and a user selectable
error correction mechanism.
The smallest element in an Aztec
symbol is called a "module" (i.e. a square dot). The
module size and the amount of error correction are the only
"dimensions" that can be specified for an Aztec symbol
and both are user selectable. It is recommended that the module
size should range between 15 to 30 mils in order to be readable
by most of the scanners that are currently available.
The overall size of an Aztec
symbol is dependent on the module size, the total amount of
encoded data and also on the level of error correction capacity
chosen by the user. The smallest Aztec symbol is 15 modules
square and can encode up to 14 digits with 40% error correction.
The largest symbol is 151 modules square and can encode 3000
characters or 3750 numeric digits with 25% error correction.
|
| MSI/PLESSEY
MSI-PLESSEY is a variable
length, numeric only, symbology. The symbology is one of the
earliest bar code symbologies ever developed and is based on a
four bit binary number scheme. Each symbol is framed by a start
and a stop pattern and contains a check character that is
calculated from the values of each of the encoded data digits.
MSI-Plessey is rarely used in anything other than grocery store
shelf marking applications. In fact most modern bar code readers
do not provide support for reading MSI-Plessey symbols.
|

